| Chapter 4 |  |

| Chapter 4 | |
Contents:
Shell Scripts and Functions
Shell Variables
String Operators
Command Substitution
Advanced Examples: pushd and popd
If you have become familiar with the customization techniques we presented in the previous chapter, you have probably run into various modifications to your environment that you want to make but can't-yet. Shell programming makes these possible.
The Korn shell has some of the most advanced programming capabilities of any command interpreter of its type. Although its syntax is nowhere near as elegant or consistent as that of most conventional programming languages, its power and flexibility are comparable. In fact, the Korn shell can be used as a complete environment for writing software prototypes.
Some aspects of Korn shell programming are really extensions of the customization techniques we have already seen, while others resemble traditional programming language features. We have structured this chapter so that if you aren't a programmer, you can read this chapter and do quite a bit more than you could with the information in the previous chapter. Experience with a conventional programming language like Pascal or C is helpful (though not strictly necessary) for subsequent chapters. Throughout the rest of the book, we will encounter occasional programming problems, called tasks, whose solutions make use of the concepts we cover.
A script, or file that contains shell commands, is a shell program. Your .profile and environment files, discussed in Chapter 7, Input/Output and Command-line Processing are shell scripts.
You can create a script using the text editor of your choice. Once you have created one, there are two ways to run it. One, which we have already covered, is to type . scriptname (i.e., the command is a dot). This causes the commands in the script to be read and run as if you typed them in.
The second way to run a script is simply to type its name and hit RETURN, just as if you were invoking a built-in command. This, of course, is the more convenient way. This method makes the script look just like any other UNIX command, and in fact several "regular" commands are implemented as shell scripts (i.e., not as programs originally written in C or some other language), including spell, man on some systems, and various commands for system administrators. The resulting lack of distinction between "user command files" and "built-in commands" is one factor in UNIX's extensibility and, hence, its favored status among programmers.
You can run a script by typing its name only
if . (the current directory) is part of your command
search path, i.e., is included in your PATH variable
(as discussed in Chapter 3, Customizing Your Environment). If . isn't on your path,
you must type ./scriptname, which is really the
same thing as typing the script's absolute pathname
(see Chapter 1, Korn Shell Basics).
Before you can invoke the shell script by name, you must also give it "execute" permission. If you are familiar with the UNIX filesystem, you know that files have three types of permissions (read, write, and execute) and that those permissions apply to three categories of user (the file's owner, a group of users, and everyone else). Normally, when you create a file with a text editor, the file is set up with read and write permission for you and read-only permission for everyone else.
Therefore you must give your script execute permission explicitly, by using the chmod(1) command. The simplest way to do this is to type:
$chmod +x scriptname
Your text editor will preserve this permission if you make subsequent changes to your script. If you don't add execute permission to the script and you try to invoke it, the shell will print the message:
scriptname: cannot execute.
But there is a more important difference between the two ways of running shell scripts. While the "dot" method causes the commands in the script to be run as if they were part of your login session, the "just the name" method causes the shell to do a series of things. First, it runs another copy of the shell as a subprocess; this is called a subshell. The subshell then takes commands from the script, runs them, and terminates, handing control back to the parent shell.
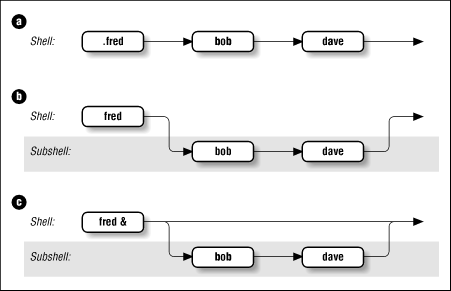
Figure 4.1 shows how the shell executes scripts. Assume you have a simple shell script called fred that contains the commands bob and dave. In Figure 4.1.a, typing .fred causes the two commands to run in the same shell, just as if you had typed them in by hand. Figure 4.1.b shows what happens when you type just fred: the commands run in the subshell while the parent shell waits for the subshell to finish.
You may find it interesting to compare this with the situation in Figure 4-1.c, which shows what happens when you type fred &. As you will recall from Chapter 1 the & makes the command run in the background, which is really just another term for "subprocess." It turns out that the only significant difference between Figure 4.1.c and Figure 4-1.b is that you have control of your terminal or workstation while the command runsmdash;you need not wait until it finishes before you can enter further commands.
There are many ramifications to using subshells. An important one is that the exported environment variables that we saw in the last chapter (e.g., TERM, LOGNAME, PWD) are known in subshells, whereas other shell variables (such as any that you define in your .profile without an export statement) are not.
Other issues involving subshells are too complex to go into now; see Chapter 7, and Chapter 8, Process Handling, for more details about subshell I/O and process characteristics, respectively. For now, just bear in mind that a script normally runs in a subshell.
The Korn shell's function feature is an expanded version of a similar facility in the System V Bourne shell and a few other shells. A function is sort of a script-within-a-script; you use it to define some shell code by name and store it in the shell's memory, to be invoked and run later.
Functions improve the shell's programmability significantly, for two main reasons. First, when you invoke a function, it is already in the shell's memory (except for autoloaded functions; see section titled "Autoloaded Functions"); therefore a function runs faster. Modern computers have plenty of memory, so there is no need to worry about the amount of space a typical function takes up. For this reason, most people define as many functions as possible rather than keep lots of scripts around.
The other advantage of functions is that they are ideal for organizing long shell scripts into modular "chunks" of code that are easier to develop and maintain. If you aren't a programmer, ask one what life would be like without functions (also called procedures or subroutines in other languages) and you'll probably get an earful.
To define a function, you can use either one of two forms:
function functname {
shell commands
}or:
functname () {
shell commands
}There is no difference between the two. Perhaps the first form was created to appeal to Pascal, Modula, and Ada programmers, while the second resembles C; in any case, we will use the first form in this book. You can also delete a function definition with the command unset -f functname.
When you define a function, you tell the shell to store its name and definition (i.e., the shell commands it contains) in memory. If you want to run the function later, just type in its name followed by any arguments, as if it were a shell script.
You can find out what functions are defined in your login session by typing functions. [1] The shell will print not just the names but the definitions of all functions, in alphabetical order by function name. Since this may result in long output, you might want to pipe the output through more or redirect it to a file for examination with a text editor.
[1] This is actually an alias for typeset -f; see Chapter 6, Command-line Options and Typed Variables.
Apart from the advantages, there are two important differences betweeen functions and scripts. First, functions do not run in separate processes, as scripts are when you invoke them by name; the "semantics" of running a function are more like those of your .profile when you log in or any script when invoked with the "dot" command. Second, if a function has the same name as a script or executable program, the function takes precedence.
This is a good time to show the order of precedence for the various sources of commands. When you type a command to the shell, it looks in the following places until it finds a match:
Keywords such as function and several others, like if and for, that we will see in Chapter 5, Flow Control
Aliases [2]
[2] However, it is possible to define an alias for a keyword, e.g., alias aslongas=while. See Chapter 7 for more details.
Built-ins like cd and whence
Functions
Scripts and executable programs, for which the shell searches in the directories listed in the PATH environment variable
We'll examine this process in more detail in the section on command-line processing in Chapter 7.
If you need to know the exact source of a command, there is an option to the whence built-in command that we saw in Chapter 3. whence by itself will print the pathname of a command if the command is a script or executable program, but it will only parrot the command's name back if it is anything else. But if you type whence -v commandname, you get more complete information, such as:
$ whence -v cd cd is a shell builtin $ whence -v function function is a keyword $ whence -v man man is /usr/bin/man $ whence -v ll ll is an alias for ls -l
We will refer mainly to scripts throughout the remainder of this book, but unless we note otherwise, you should assume that whatever we say applies equally to functions.
The simplest place to put your function definitions is in your .profile or environment file. This is fine for a small number of functions, but if you accumulate lots of them-as many shell programmers eventually do-you may find that logging in or invoking shell scripts (both of which involve processing your environment file) takes an unacceptably long time, and that it's hard to navigate so many function definitions in a single file.
The Korn shell's autoload feature addresses these problems. If you put the command autoload fname [3] in your .profile or environment file, instead of the function's definition, then the shell won't read in the definition of fname until it's actually called. autoload can take more than one argument.
[3] autoload is actually an alias for typeset -fu; see Chapter 6.
How does the shell know where to get the definition of an autoloaded function? It uses the built-in variable FPATH, which is a list of directories like PATH. The shell looks for a file called fname that contains the definition of function fname in each of the directories in FPATH.
For example, assume this code is in your environment file:
FPATH=~/funcs autoload dave
When you invoke the command dave, the shell will look in the directory ~/funcs for a file called dave that has the definition of function dave. If it doesn't find the file, or if the file exists but doesn't contain the proper function definition, the shell will complain with a "not found" message, just as if the command didn't exist at all.
Function autoloading and FPATH are also useful tools for system administrators who need to set up system-wide Korn shell environments. See Chapter 10, Korn Shell Administration.
|  | |
| 3.6 Customization Hints |  | 4.2 Shell Variables |